Smarter Runner Lifecycle Management
GitHub Actions is one of the most widely used CI/CD tools among Orka customers. Teams building iOS and macOS apps rely on it daily to run builds, tests, and release pipelines — which means the Orka GitHub Integration sits right in the critical path of their development workflow.
That's exactly why we took a hard look at runner and VM lifecycle management in version 1.1.11. When something in the integration behaves unpredictably, developers feel it immediately. This release is a significant rewrite focused on making runner provisioning more reliable and resource cleanup automatic, so the integration stays out of your way and lets your pipelines do their job.
Here's what changed and why it matters.
How the Integration Works
Before getting into the changes, a quick refresher on the two core objects at play:
- GitHub Runner — the agent that picks up and executes GitHub Actions jobs
- Orka VM — the macOS virtual machine the runner runs on
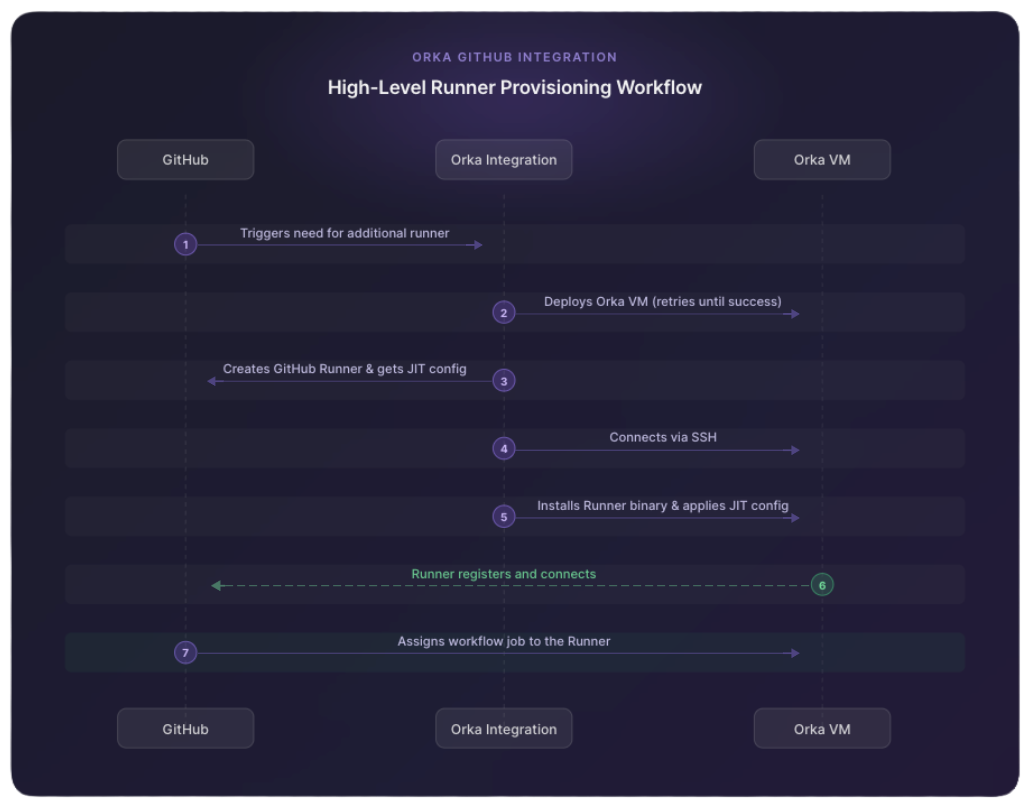
When the integration detects that more runners are needed, it provisions a new VM, installs the GitHub Actions runner binary on it via SSH, and uses a Just-In-Time (JIT) config to tie that VM to a specific GitHub runner. Once that pairing is complete, GitHub can assign jobs to it.
One side effect of this design: over-provisioning is possible. If all pending jobs finish before GitHub schedules a new one, you can end up with a Runner–VM pair sitting idle. That's expected behavior. The next job goes straight to that runner without the integration needing to spin up a new one.
What's Improved
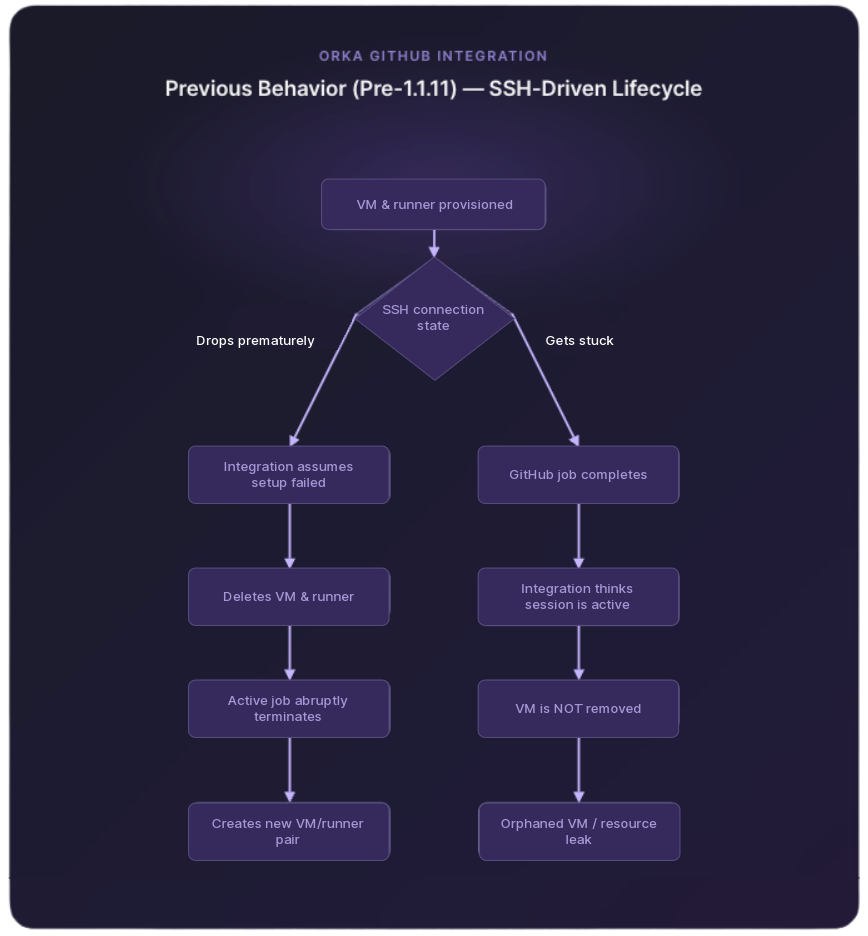
Previously, the integration relied on SSH connection state to decide whether a VM was still needed. Version 1.1.11 replaces that with something more reliable: GitHub job lifecycle events.
This change directly addresses two scenarios that could disrupt your pipelines.
SSH drops during or after setup: The VM is no longer deleted on a dropped connection. The integration now waits for GitHub to confirm the job is finished before cleaning anything up. Running jobs stay running.
SSH gets stuck: Once GitHub reports the job is complete, the integration deletes the runner and VM, regardless of what the SSH session is doing. No more VMs lingering after a job finishes.
What Changed in 1.1.11
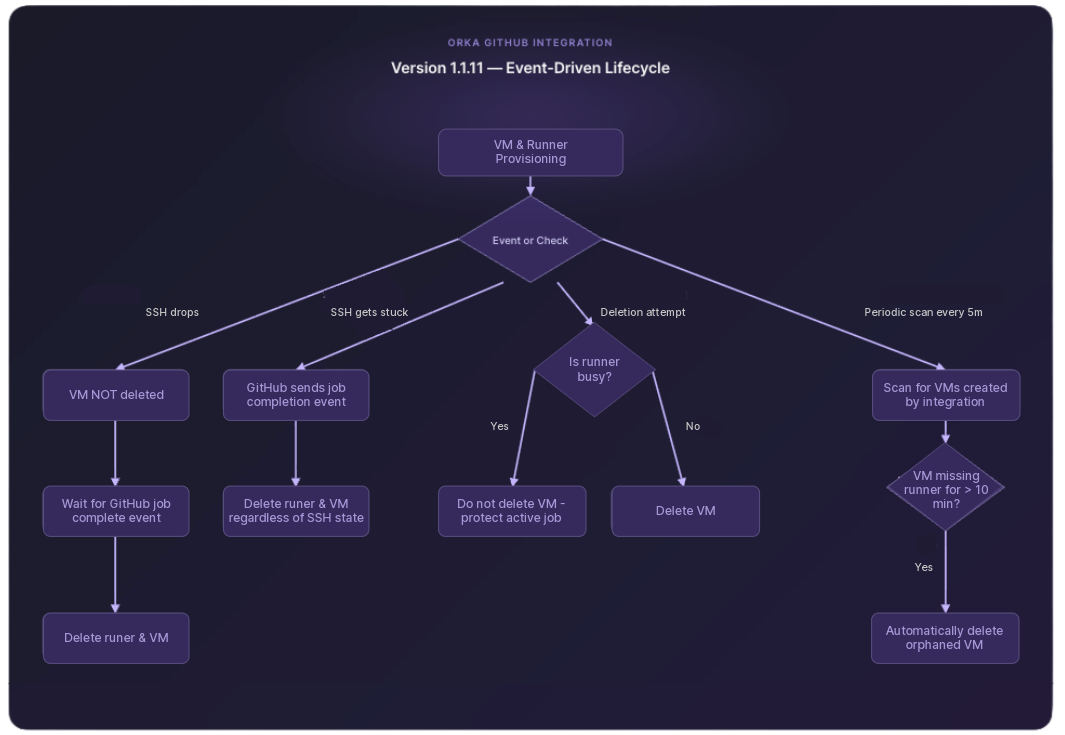
The core change is this: VM lifecycle is now driven by GitHub job events, not SSH connection state.
SSH is still used to set up the runner. But what happens to the VM after that is no longer tied to SSH behavior.
Here's how the new logic handles each scenario:
SSH drops during or after setup: The VM is not deleted. The integration waits for GitHub to report that the associated job has finished, then removes the runner and VM cleanly.
SSH gets stuck: Once GitHub sends a job completion event, the integration deletes both the runner and the VM, regardless of what the SSH session is doing.
Deletion attempts on busy runners: Before deleting any VM, the integration first checks whether the associated GitHub runner is busy. If it is, the VM is left alone. Active jobs are never interrupted.
Automatic Orphaned VM Cleanup
As an additional safety net, 1.1.11 adds a periodic background scan for orphaned VMs.
Every 5 minutes, the integration looks for VMs that no longer have a corresponding GitHub runner. If a VM fails that check twice (meaning it's been running for more than 10 minutes with no runner attached) it's automatically deleted.
This cleanup only targets VMs that the integration itself created. Other VMs in your cluster are not touched.
Upgrading to 1.1.11
The upgrade process is the same as any previous version. No special migration steps are required.
One thing to do before upgrading: make sure no workflows are currently running. That ensures no active runners are terminated mid-job during the upgrade.
The Bottom Line
With these changes, the Orka GitHub Integration now handles the two most common failure scenarios cleanly:
- SSH instability no longer kills running jobs or leaves orphaned VMs behind
- Cluster resources are recovered automatically, without manual intervention
Runner lifecycle management is more predictable now, even when the underlying SSH behavior isn't.
For full documentation on the Orka GitHub Integration, visit MacStadium Docs.